This is another blog about a project that I worked on, why I did and what I learned from it. This time I wanted to think about discovery. Say I'm reading a blog and I really like it and want to find more authors who talk about this stuff. Of course, discovery this should never be automated. It should always be initiated from the person. There is a unique joie de vivre that you get when you discover a great read or just looking into stuff. But this is an experiment. I wanted to see if I could aid the discovery process with something like this.
What I wanted and where I got.
I wanted to make a simple graph based exploration / visualization of articles and maybe even recommend authors to you based on your reading. Maybe you could even trace your steps. Rajan, Freeman and Leo did something very similar to this at TreeHacks and so I decided to fork their repo and try it out myself. I think I did all right. Its something I cooked up in a weekend and its nowhere near production ready.

Essentially, its an interactive graph where each node is an article and each link is a connection between articles. Each article recommends authors to refer to. There are 1800 articles in this graph.
Process
So the process was essentially broken down into 3 stages
- Acquire the data (i.e articles to work with)
- Find ways to connect blogs and authors who talk about the same concepts together
- Display this as an interactive graph.
Luckily 3 was taken care of in the Nexus project. I would hate to have to do frontend work. So its essentially the following (Freeform is genuinely goated.)
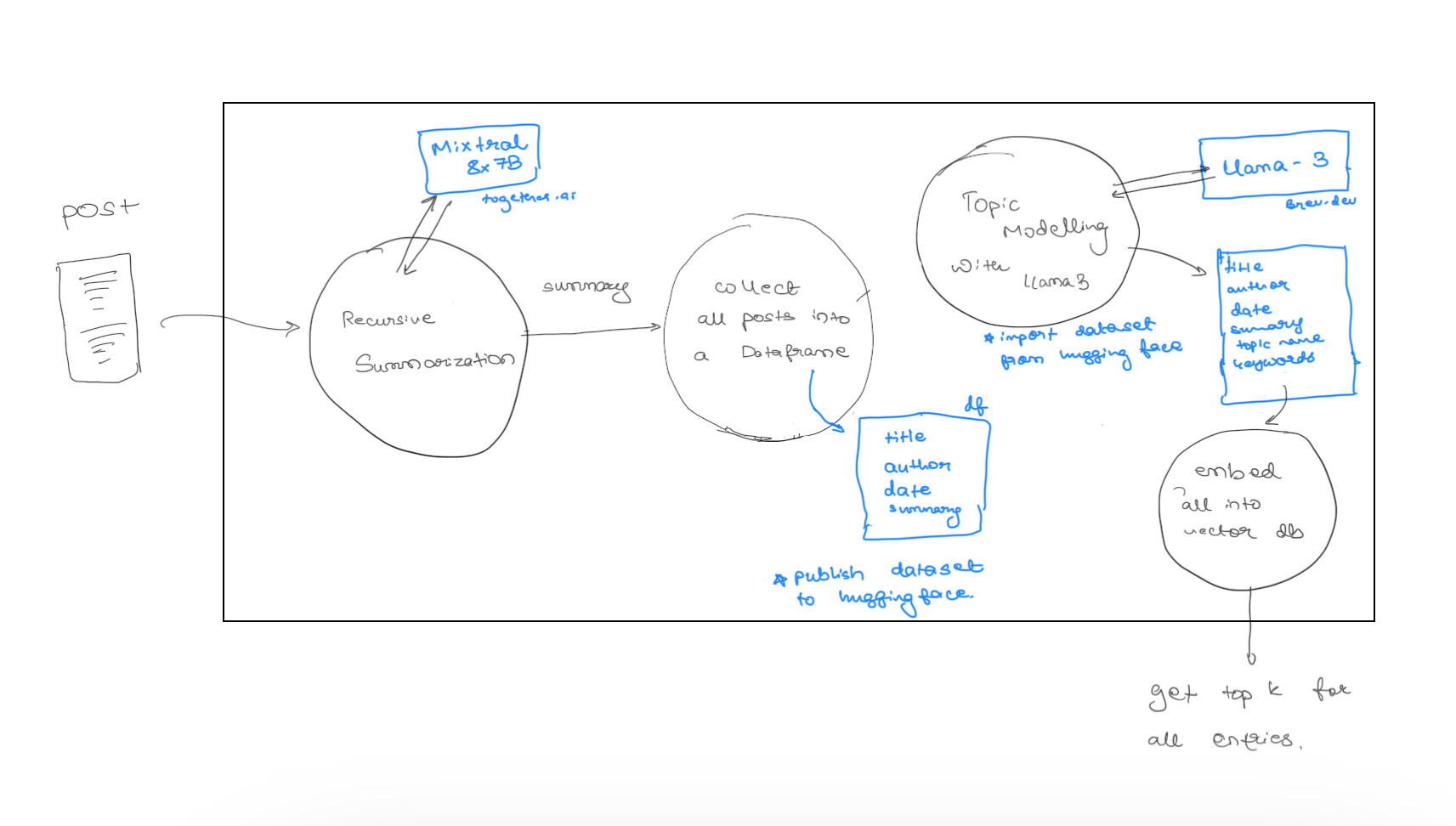
While working through this, I had an itch to try and make it as modular as possible and maybe through a couple classes here and there called Post or Author or Concept that forms a graph and then we serialize it. But then I remembered this good ol' graph
So I stuck to keeping it dead simple. Bunch of python scripts to just do one thing and one thing well. Downloading the data wasn't that hard. I found a nice
Golang executable here. I managed to modify it to give me the metadata like the title, subtitle, post date, etc.
This was incredibly slow though. I tried a Rust equivalent but it used the RSS feed instead of the sitemap.xml to extract
the URLs so it only got like 10% of the actual number of posts. I tried forking it and making the changes myself but it got too tedious
(as Rust usually does) and so I just stuck with the Golang one. Onto topic modelling and embeddings.
Attempt 1: Semantic Clustering based on title alone
This method was my knee-jerk plan to cluster. However, I quickly abondoned this method because of Ava from bookbear express. She has some of the best writing I have ever seen and the titles of her posts are entrancing but not very informative. Embedding models will take a sentence at face value. There is no rationale searching for what it could mean or what it hints at like we humans do. So this method would fail miserably. Many articles that should be connected will not be because of this naive approach. We needed to look deeper. Now current models don't have reflections and systems to do so aren't production ready and would take some engineering for me to make. So the only option left, afaik was to extract the topics and match based on these topics.
Attempt 2: Topic Modelling with Llama-3
I ran an experiment with topic modelling to know if this could be suitable to model topics for all my blogs. I decided to use BERTopic and augemented with Meta's brand new shiny LLM Llama-3-8B-Instruct. So got cracking with brev.dev. Got myself an A10G and 32GB system memory. No longer GPU poor, eh. Ran an experiment with abstracts of ArXiV papers which was a good starting point. Its close enough to what I need it for anyways.
Got very promising results

I was smiling ear-to-ear when I saw these results. I nailed it I said to myself. Then I tried my dataset. Keep in mind, I had 500 blogs in the dataset that I was experimenting with (a small chunk of my planned dataset of 10k). Reason for this is I'm keeping in mind one of my other lessons. So what happened when I ran this experiment ?

Learned an important lesson today about data. I'll talk about that later. I initially thought it was cause of the data sample being so small (only 500). HBDSCAN may not have been able to cluster well enough. I tried it again with a 1500 size dataset to no avail. This was a cooked approach.
Attempt 3: Falling back to LLMs
After the miserable failure with Topic Modelling, I thought about what else to do. The most obvious approach would be to just ask an LLM to find the topics by reading the text. Well damn. That was simple enough. So I got to doing that. Of course it took miserably long. Over an hour for the 1500 dataset. But I had no choice. It literally just came down to this
def query_claude(original_text: str) -> dict[str, list]:
...
message = client.messages.create(
model="claude-3-haiku-20240307",
max_tokens=1024,
system="""
You are a topic identification bot. You are tasked with reading a text and coming up
with topics that are discussed in the text or abstract concepts. These should be short and terse.
If there any authors referenced, add them as well. Answer ONLY in JSON with 2 keys, "topics" and "references" like so
{
"topics": []
"references": []
}
""",
messages=[
{"role": "user", "content": f"The text is provided below \n{original_text}"}
]
)
...
Lessons Learned
- Data decides the method
I am confident the readon that Attempt 2 did not work was because of the sheer lack of data. The topic model could not find enough clusters with the 500 and 1500 dataset I gave it. It only showed some results at 3000. The ArXiV dataset contains 118K points. I mean my dataset is peanuts compared to that. No wonder the topic model did so well with it.
- When you have a lot of data (relative to your task), you can then opt for more niche methods and experiment with custom models / methods.
- When you have (relatively) small dataset, opt for using "vanilla" methods like calling Claude or GPT4. Prompting does wonders sometimes and these models can get you far.
Even before you acquire the data, you need to plan for each contigency. Don't overplan this. Have a strategy in mind. Once you get the data and have checked if its good, you need to make the distinction above before carrying out the experiments. It will save you time and money
- Data versioning is priceless
They say a picture says a 1000 words. Let me paint you one

Whenever I do ML in production, I will be sure to use some data and model versioning software. Need to start experimenting with them next.
- Uninitiated discovery must be accompanied by reasons. No quarter.
I believe that more and more software in the future will be geared towards discovery. Essentially, AIs discovering things for you in the downtime and them recommending them to you. I experienced this right now. After perusing through the semantic graph it becomes obvious that these recommendations and connections mean nothing without the rationale for what they are there.
As humans, when we freely explore and discover, we make semantic connections ourselves. But when an AI does it for us, it bypasses the semantic connection phase and gets us straight to the information display phase. Now nothing can replace the semantic connection phase but we can come close to it by giving explicit and detailed reason as to why these connections were made. For example

Like, I want to know why Ava and Alex Mathers have this connection. Not just a surface level "Oh they both talk about X" - it has to be a, "they both concur about X and take so-and-so approach to talk about their premise", etc. PKM would benefit greatly from this.