The Come Up
My exams and final projects just got over and walking back, the crisp and the weight off my shoulders helped me think about what to cook up next ? I have been experimenting and learning a lot about ML models both because of CV course and side projects. CLIP was a recent fascination of mine. The very idea that we could simply extend a model's understanding of image features by training it with language.

Now, I also love movies and FILM-GRAB has one of the most comprehensive movie still archive. So I naturally got thinking - why not treat this as a contrastive learning problem ? Extract each of the scenes from the movies and then train a model to do zero-shot classification on it.
The Cook
Now although this blog is published on Jan 31st, 2024, I wrote most of it while I was coding on December 10th. Kinda Zuck-Social Network style. I have had some issues with deployment and captioning and frontend (to say the least), so all of those were written after the exams got over.
This project was broken down into 3 different sections
- Dataset : generating the 180K movie scene dataset.
- Model : fine-tuning CLIP for zero-shot classification.
- Search : building a movie-scene search engine using dual embeddings from the model.
You can check out the whole repo here.
The Dataset
So the process for collecting the data was simple
- build a webscraper that can scrap FILMGRAB.
- use the OMDB API to extract movie metadata based on the movie name
- collect all the images per IMDB ID.
- store all the images and the movie metadata
- caption all the images and store the image->caption mapping.
Images
To do this was pretty straightforward. I made a simple web scraper that uses bs4 to extract all the images present in one webpage in FILMGRAB. This is then done for all the webpages linked in their A-Z Section. Now it took about 2 minutes to download images from one webpage. Given that there are 3000 movies, there is no way this is getting done in one night.
Enter mulithreading. I had to make it a producers-consumers problem. So this took me about another 2-3 hours to make it a producers consumers problem. Ran it at a smaller scale with 10 producers and 50 consumers and then it did 200 movies in approximately 7 minutes.

Great, onto the next.
Metadata
This was a little tricky. I had to use the OMDB API but it only allowed me to do 1000 requests per day. No way I could complete it all in one-night. Maybe I could be smart and do it over 3 days making sure to never repeat movies that are already downloaded. ORRR. I could get the 2$ patreon membership and get access to 100,000 requests per day. I took the second cause I'm lazy and I want results.
So now, everytime a movie is downloaded it will query the OMDB API, get the metadata, process the directors, genres, etc. and then keep it in the dictionary. We get a neat dictionary like this for each movie
"tt0083658": {
"Title": "Blade Runner",
"Year": "1982",
"Rated": "R",
"Released": "25 Jun 1982",
"Runtime": "117 min",
"Genre": [
"Action",
"Drama",
"Sci-Fi"
],
"Director": [
"Ridley Scott"
],
"Writer": [
"Hampton Fancher",
"David Webb Peoples",
"Philip K. Dick"
],
"Actors": [
"Harrison Ford",
"Rutger Hauer",
"Sean Young"
],
"Plot": "A blade runner must pursue and terminate four replicants who stole a ship in space and have returned to Earth to find their creator.",
"Language": "English, German, Cantonese, Japanese, Hungarian, Arabic, Korean",
"Country": "United States, United Kingdom",
"Awards": "Nominated for 2 Oscars. 13 wins & 21 nominations total",
"Poster": "https://m.media-amazon.com/images/M/MV5BNzQzMzJhZTEtOWM4NS00MTdhLTg0YjgtMjM4MDRkZjUwZDBlXkEyXkFqcGdeQXVyNjU0OTQ0OTY@._V1_SX300.jpg",
"Ratings": [
{
"Source": "Internet Movie Database",
"Value": "8.1/10"
},
{
"Source": "Rotten Tomatoes",
"Value": "88%"
},
{
"Source": "Metacritic",
"Value": "84/100"
}
],
"Metascore": "84",
"imdbRating": "8.1",
"imdbVotes": "811,253",
"imdbID": "tt0083658",
"Type": "movie",
"DVD": "09 Jun 2013",
"BoxOffice": "$32,914,489",
"Production": "N/A",
"Website": "N/A",
"Response": "True",
"NumImages": 60
}
Captioning
This was a whole differenent ball-game. I wanted to caption the images automatically (I mean who in their right mind is going to manually caption 180K images). So naturally, I turned to some image-captioning models for help. Salesforce/blip-image-captioning-large stood out to me and I decided to use the same producers-consumers mentality and crack this one.
I had setup the captioning.py file to achieve this and had makde a small
Now you can download the dataset yourself by the following instructions
wget https://moviescene-dataset.s3.us-east-2.amazonaws.com/moviescene_2024_01.zip
unzip moviescene_2024_01.zip -d dataset/
The Model
This was the most challenging part of the process. I have trained models before and built custom models before but fine-tuning poses its own set of challenges and I had a new set of issues with this process. Learned a ton though.
So it started with a lot of research of fine-tuning. The most useful are linked below:
But of course, no plan survives contact with the enemy. I started with loading the data via Pytorch's Dataloader. Now since I don't want to bork my system by loading 180K images, I decided to do sci-fi movies which was 250 movies with approximately 15000 images for training. Everything looked to be in order. For the most part.
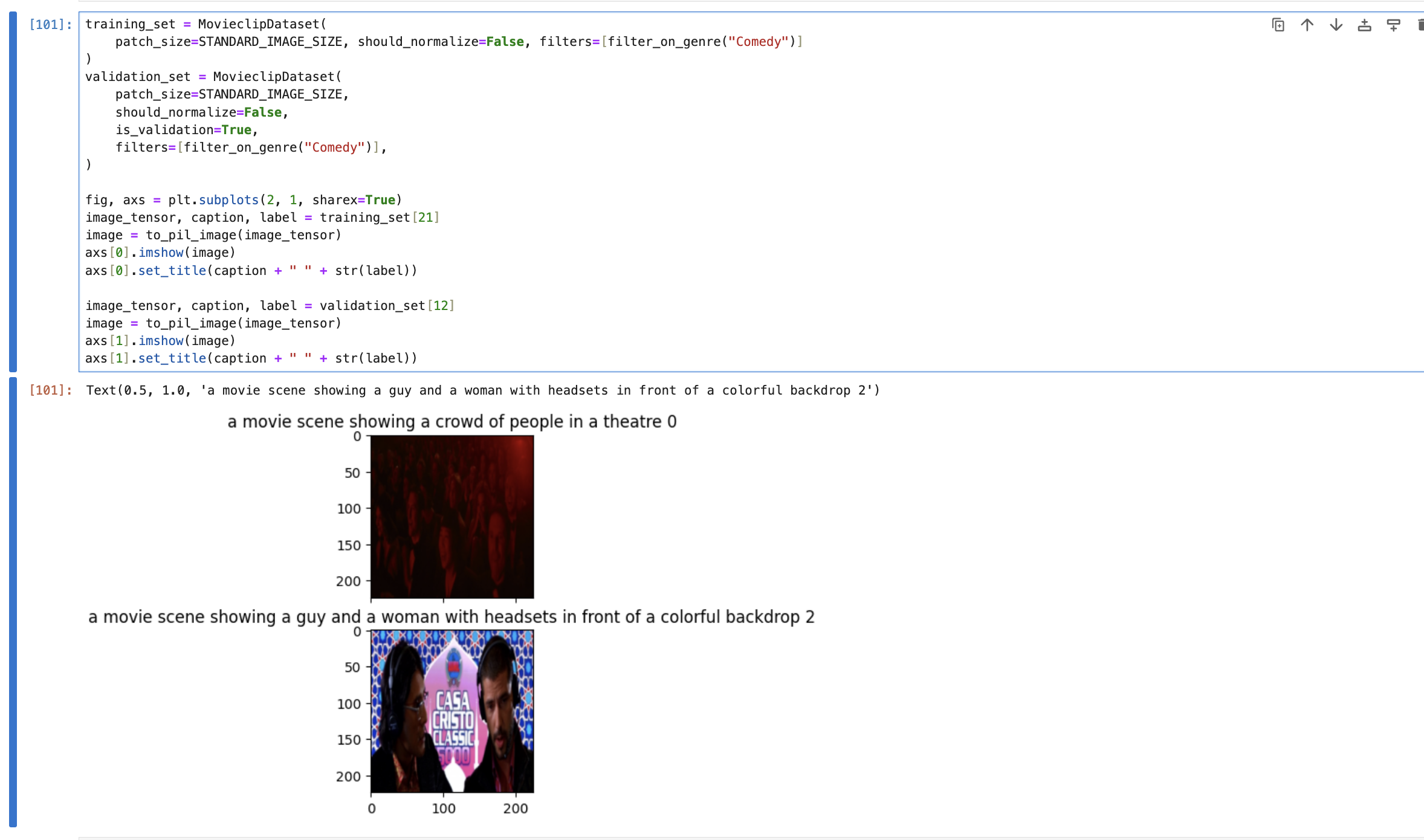
Now the model training part was especially tough because I got some exploding probabilities issues. I am quite sure this is because of the labels and the way I set up the
classification. I just get nan for the logits and the probabilities.
I spent about the next couple of days on this and I think if I deep it for a week or so I would be able to fix it but right now I don't have the capacity. I'll have to come back to this at a later date. But I can still make the search engine without this specialized model so that's there.
A little disappointed in myself. But I'll get it right soon.
The Search Engine
Now for this I chose to use
- Next.js
- Chakra-UI
- Typescript
for the frontend and FastAPI for the backend. Qdrant as the vector store. Nothing too fancy. No ornaments. Just wanted something to let me cook as easily as possible.
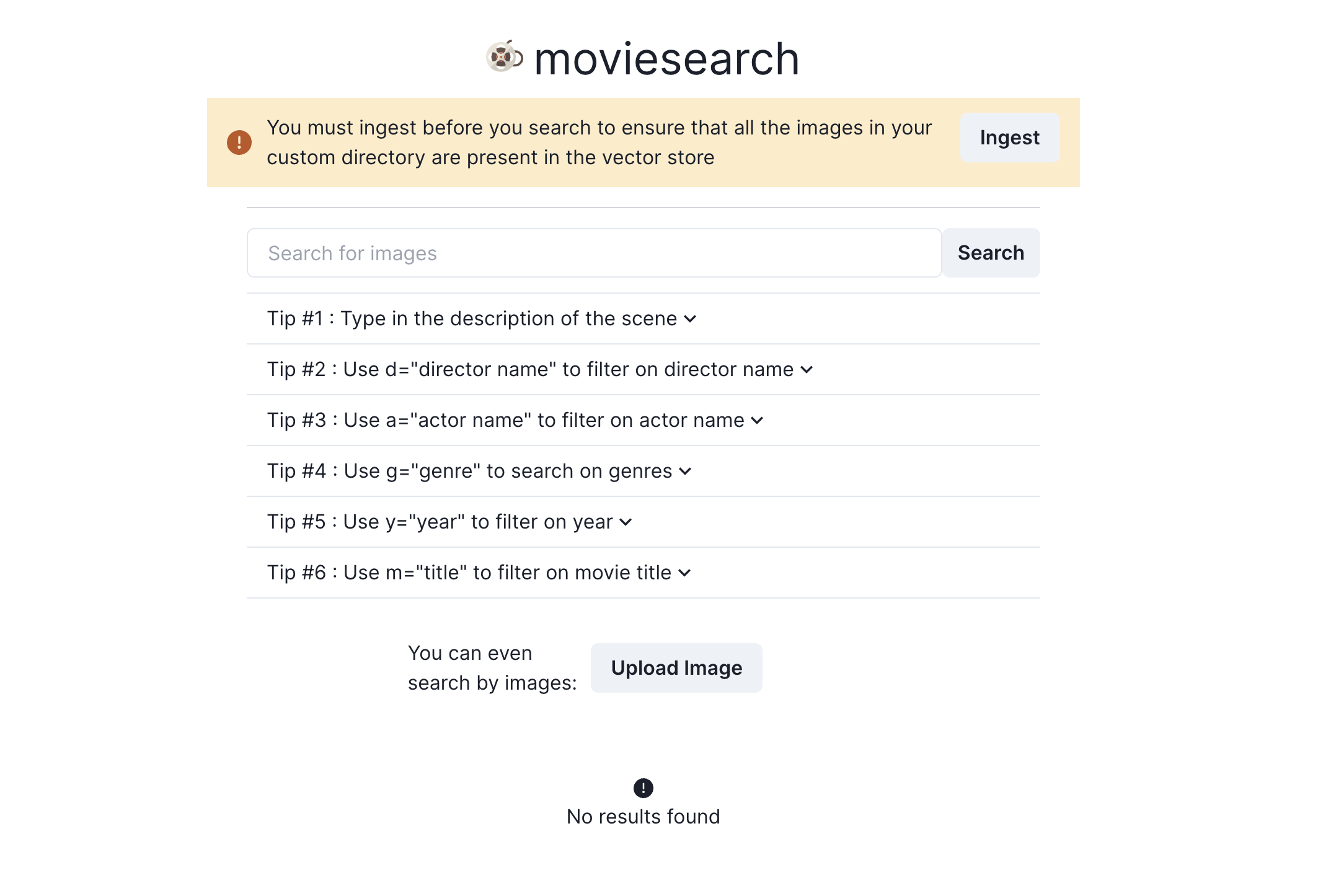
Setting this up was really straightforward. I managed to do most of the frontend work in the new year. The only problem is that I'm hopeless when it comes to frontends so shoutout to GPT-4.
Lessons Learned
Some of the lessons learned from this are
- Don't be cheap when it comes to compute.
Seriously Ebenezer Scrooge, don't try and be cheeky. I'll just put a screenshot of the captioning endpoint and you'll see it.
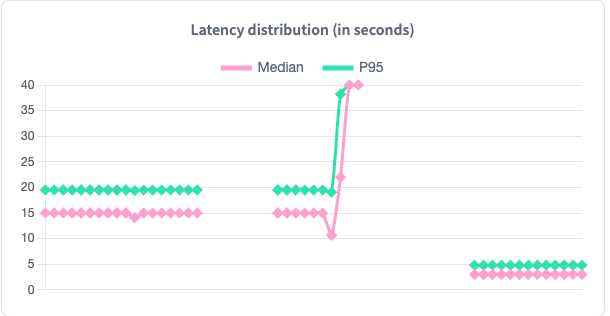
The drop you see is when I switched from a T4 to an A10G GPU. I had an eye-watering 14s latency per-image for captioning with the T4 meaning it was ~10 min per movie. With the A10G, that dropped to around 2s median latency. That is world of a difference. So once again, shell out a couple more bucks.
- Run everything end-to-end at a smaller scale.
I had this issue with the dataset generation. I would run each of the different sections (downlaoding, metadata, captioning) seperately and I only did individual end-to-end tests. Doing so was fine for prototyping but when I ran the script, I really started to understand the importance of the end-to-end runs. What I should have done was made a flag called "Demo" or something that when raised would do the whole shebang for about 200 movies or so. This would have helped me spot bugs and iron out details so much quicker.
- Checkpointing. Checkpointing. Checkpointing.
In two occasions, I realized how important this is. First when making the dataset. I should have written to the files at every 500 movies downloaded. So many hours I've wasted by reruning the download scripts.
Second when doing the model training, checkpoint every at some training or loss milestone is really crucial. Resuming training or even using older checkpointed models for some initial prototyping can be immensely useful.
- Read the concepts page in addition to the API reference
I think this is more of programming in general statement than a "movieclip"-specific lesson. Whenever a project or some framework has a "Concepts" page or something akin to it, do read it. Not only does it imbibe a deeper understanding of the framework, but you have a understanding of some of the salient features of the framework. This came in particurly clutch for Qdrant and Next.js.
- We need a universal scraper that operates like our eyes
Seriously, we do. The amount of fragmented HTML classes on the internet is eye-watering. Quite literally. I had to spend hours to figure out why my scraper was not downloading images, modify it slightly,
sprinkle if-else conditions here and there - just to watch it break sometime later. Sigh. if-else. Repeat. There HAS TO BE A BETTER WAY. Maybe LAMs are the way. Maybe vision models are the future. All I
know is that it has to get better.
So that's all folks! See you next time.