Reasoning in Large Language Models
In the realm of artificial intelligence and natural language processing, the rise of large language models like GPT-3 has been nothing short of revolutionary. These models, powered by deep learning techniques, have demonstrated impressive capabilities in understanding and generating human-like text. But one question that has often puzzled researchers is how to make these models think more deeply, reason, and solve complex multi-step problems effectively. In this blog post, I want to explore what "Chain-of-Thought Prompting" and "Tree-of-Thought Prompting" can give us and what next from there.
Furthermore, I want to propose an idea I have for reasoning via working memory, called "Labyrinth-of-Thought". I have learned a lot about human working memory and executive function through my neuropsychology course (PSYCH 307 - highly recommend) and since I am exploring Deep Learning and LLMs I naturally think of applying these "human" elements to models.
Understanding Chain-of-Thought Prompting
In essence, a "Chain-of-Thought" prompt involves a series of interconnected queries or prompts, each building upon the previous one. The idea is to encourage the model to think through a problem or task in a step-by-step manner, gradually refining its responses as it progresses along the chain. This approach aims to make the model's responses more coherent, contextually relevant, and capable of reasoning through complex tasks.
The paper on "Chain-of-Thought Prompting" paper by Wei et. al introduced the idea of having models write their "thoughts" down and use them to tackle the problem at hand - specifically arithmetic problems because they are neatly decomposable.
The authors stated that endowing language models with a chain of thought - "a coherent series of intermediate reasoning steps that lead to the final answer for the problem". The authors themselves specifically lay out why CoT is naturally a better approach to facilitate reasoning.
- Decomposability - the model would decompose its approach and lay out a methodology for how it got its answer. By explicitly stating its "thought process", the model can refer back to a previous thought to generate the next and so on instead of it happening implicitly in the weights. Admittedly, the authors don't know why this helps the model but it somehow gives the right answer for tasks involving arithmetic reasoning.
- Explainability - the model can explain why it gave the answer it did. In a standard Input-Output (IO) Prompting model, when the model gives a wrong answer, neither you nor the model can explain why this is the case but in a CoT situation, you can point out a flaw in reasoning in one of the intermediate steps.
- Manipulation - this can be used for symbolic manipulation and math tasks as described in the paper.
- Few-shot Prompting - by using examples of CoT within the prompt, the model can perform better in more abstract/arithmetic reasoning tasks.
Affordances
Now, what abilities does this give models? Why do this really ?
Even though LLMs can write haikus and provide proofs for theorems in my combinatorics class, it is hopelessly incapable of symbol manipulation. Gary Marcus ardently protests that these models are not actually reasoning and next-token prediction is a useful and thrilling "simulation" of human-level thought.
Although I don't take as hard a stance on it as he does, I think there are more breakthroughs and methods necessary to achieve reasoning and symbolic manipulation. CoT allows LLMs to replication what elementary kids are taught to do. To break the problem down and to take an iterative approach based on intermediate results. This is extremely useful as a setup for the next major kicker - Tree of Thought.
Exploring Tree-of-Thought Prompting
Tree-of-Thought (ToT) Prompting is a tree-search used by LLMs for storing and retrieving answers to aid in reasoning. In essence, this approach functions akin to a branching tree structure, allowing the model to generate more focused and coherent responses by guiding its thought process along specific paths. It operates by providing sequential prompts that progressively narrow down the scope of information or guide the model's understanding toward a particular direction.
The following image is obtained from the ToT paper.

In the image above, the model initially generates a series of preliminary thoughts based on the prompt. We then ask it to evaluate its response alongside the prompt. Yannic Kilchner made an excellent video about this and he stated that ML in general is better at evaluating whether two things fit together under the same roof rather than generating something new. So naturally, asking a model to evaluate how useful its responses are to solving a prompt and taking the best approach from thereon seems to be a good strategy.
After evaluation, it picks the best one and explores that further.
Backtracking
A crucial feature of this is that it allows backtracking based on the quality of the answers generated in the next layer of the tree. Say for example, in the first layer, T2 is the most promising.
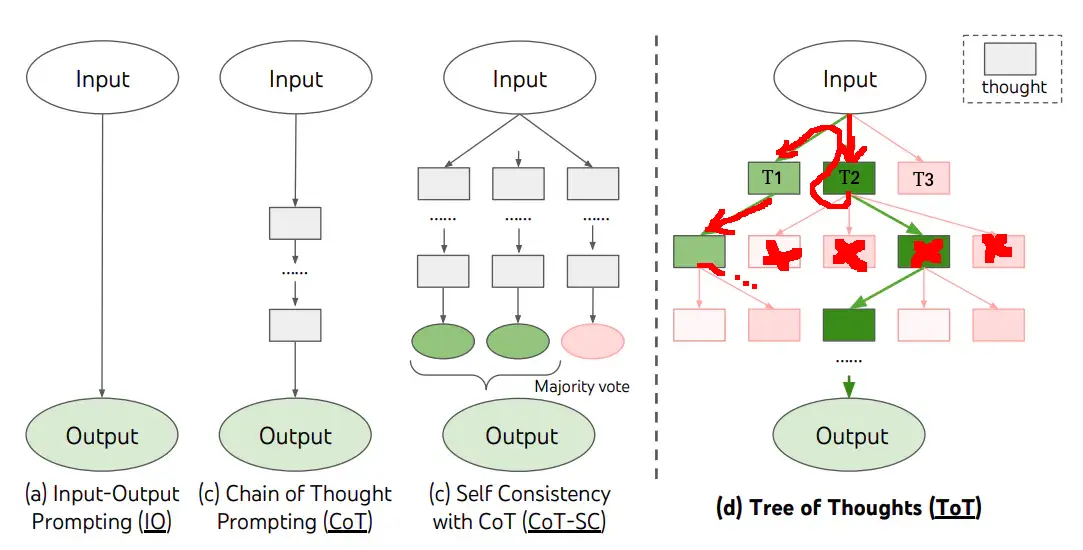
But if T2's generated next answer doesn't meet the quality threshold, then the algorithm will backtrack and go to the next best answer (T1). This is very important and I will explain why next.
Affordances
Once again, why do this ?
CoT allowed intermediate steps and decomposable thinking. ToT affords arborization of thought - very much like humans. We do not latch onto one single stream of thought and go down the rabbit hole. Instead, we have multiple ideas and several strategies. Then we do an implicit weighting of these strategies based on the task at hand and try and work it out. More importantly, if one of our strategies do not work out, we simply use another one we thought of.
ToT now gives models the ability to explore multiple ideas. This multifaceted approach to problem-solving is a big jump towards human-level reasoning but it is not enough and I will elaborate why.
Reaching for Labyrinth-of-Thought Prompting
Integrating ToT and CoT is the closest we can come to "emulating" (note the importance of the air quotes) human-level reasoning for these LLMs. However, there remain 2 key steps left over
- Lessons
- Sketching
I call this integrated approach (ToT + CoT + Lessons + Sketching) a Labyrinth-of-Thought mechanism, named after the famous story of Theseus and the Minotaur. Here I frame the minotaur as human-level reasoning and our LLMs as Theseus (it's anyone's guess how the analogy extends to Ariadne). LoT is the thread that Theseus will use. It's just a fancy name. Don't think too much of it.
"What does it all mean, Keane?" I hear you ask. In the following subsections, I will explain in full what I mean by Lessons and Sketching and how they integrate. Before I do that, I want to explain why exactly I thought of LoT.
Background
Thanks to my neuropsychology course, I've learnt a whole lot about human working memory and executive function and how is it that we keep thoughts and perceptions in memory. The following diagram is a useful reference for it.
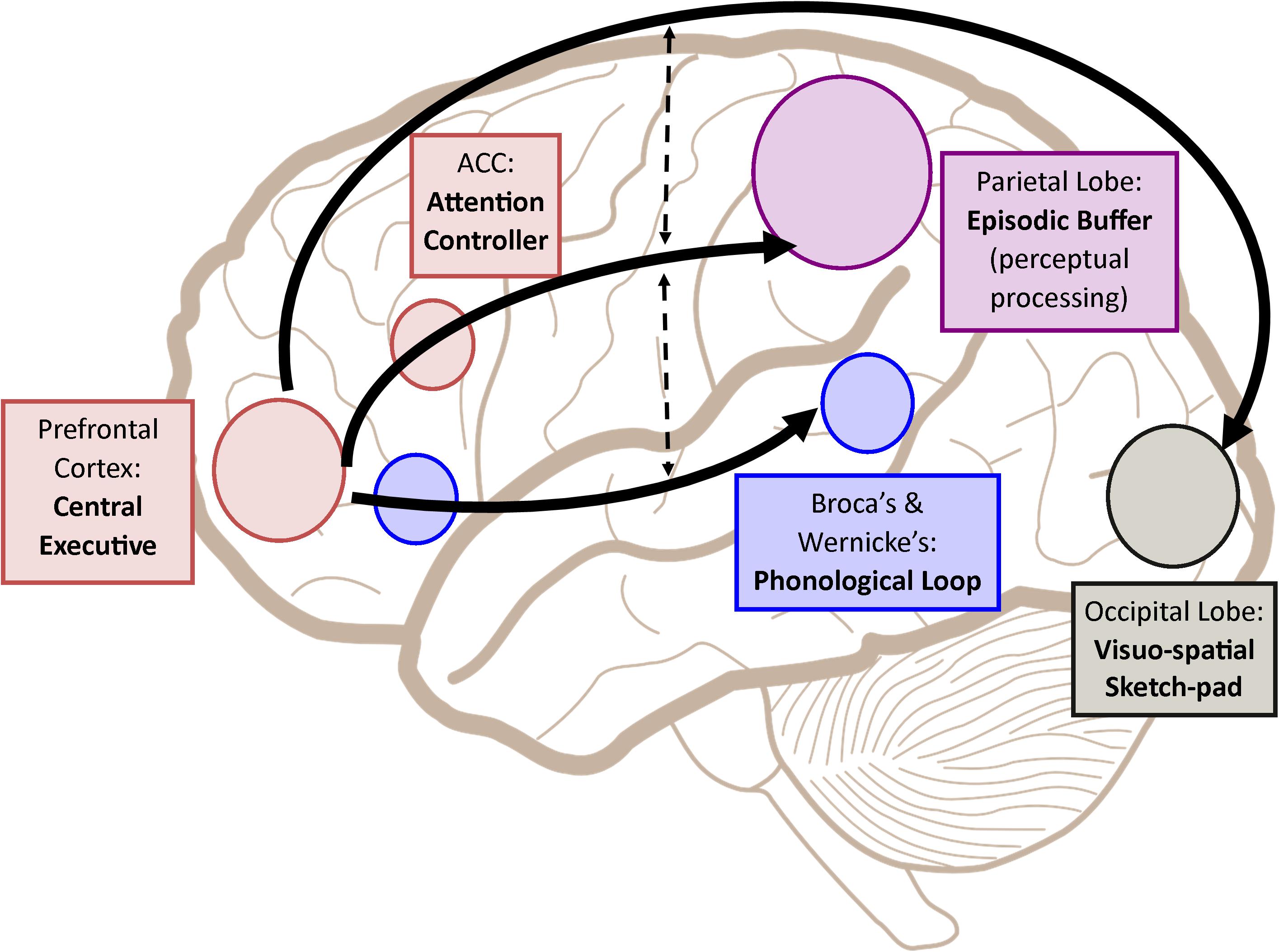
- The Phonological Loop (PL) is where verbal information is temporarily held.
- The Visuo-Spatial Sketchpad (VSS) is where visual and spatial information is held. It also serves as the location where we manipulate said images in our minds.
- The Prefrontal Cortex (PFC) is like the CPU. It decides on what information is retained and what is discarded. It is in constant communication with the PL and the VSS for updates and new information.
Now, given this cyclical structure of working memory for reasoning tasks in humans, why can't we take this approach to LLMs? What are the advantages and disadvantages?
Lessons
What are Lessons? ToT gives us arborization and a multi-pronged approach but when we humans do that, we learn key insights along the way - even if the approach does not work out. Sometimes especially if the approach does not work out. Then when we try something new, some of the insights we gain from the failed approach come in handy.
LLMs cannot leverage this. Once an approach is abandoned, its "lessons" and the responses generated are discarded. I found this to be quite wasteful and altogether misguided. The solution? A MemGPT style approach.
When you find that some solutions are not panning out, communicate this to a (PFC). Some kind of coordinator of thought. This coordinator would then place this in some "storage" mechanism. When a new line of thought is initiated, the LLM will ask the coordinator for relevant "lessons" (I still don't know how the relevancy will be decided). The coordinator looks in "memory" and then provides the LLM with the respective information.
Sketching
Now let's look at how LLMs sketch. Not physically sketch. Mentally sketch. We humans ideate and create and use tools like pencils, pens and paint to give these creations permanence. However, we don't immediately start by painting all of Water Lillies. We start with a rough sketch. A base. Then incrementally add more features. Then a splash of paint here and a dab there and then BAM! It's in the Orangerie.
Similarly, LLMs need to have some sketchpad. Not as elementary as CoT. Something more dynamic. As it goes along its tree, it adds more and more sketches. However, it understands which sketch corresponds to which thought. These sketches can be discarded but I have a feeling that if we want to build AGI, it shouldn't. There should be some mechanism for storing it.
Conclusion
There you have it. My take on the next step to LLM reasoning. I would love to build this and write a paper but sadly I am on a full course load and already committed to another project here in Waterloo, Canada. I hope I can return to this some other day. I hope its as exciting I've seen in my dreams. I hope some big brain somewhere on Mount California reads this and finds it insightful. I hope (in Morgan Freeman's voice at the end of Shawshank).